前言
今天某Y想分享一篇来自自何恺明大神组的CVPR2019的文章,并通过该文章谈下关于如何讲好一个故事的个人感受。在故事线上,某Y做了一些调整以方便讲述。
背景介绍
这篇文章首先描述了一个很有意思的现象:在遭受对抗攻击(adversarial attack) 时,卷积神经网络(CNN)会对图像的理解产生偏差。
对抗攻击是指对图像加入小幅度的扰动,来诱使判别器对其作出错误的判断。值得注意的是,此处的小幅度是指人眼难以觉察到的程度。
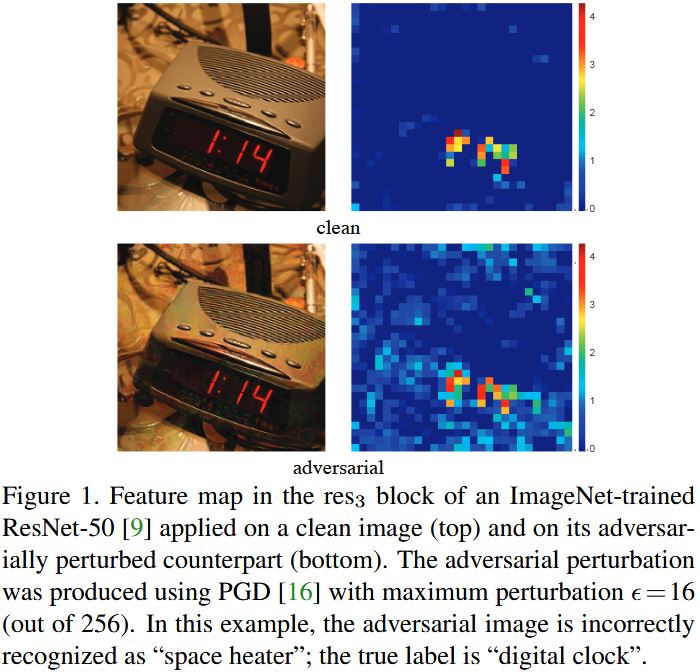
通过下图我们可以看到,即便是在人眼感受上很小的扰动,依然会致使网络做出错误的判断(将“电子钟”误检成“加热器”)。这就不得不使得人们开始思考:
- 现实世界中可能存在这样的潜在威胁。(想象一个基于DL的人脸识别系统能够轻易地被戏弄。阔怕)
- 网络的运算处理和人脑有着很大的区别。(人脑还是很厉害的!)
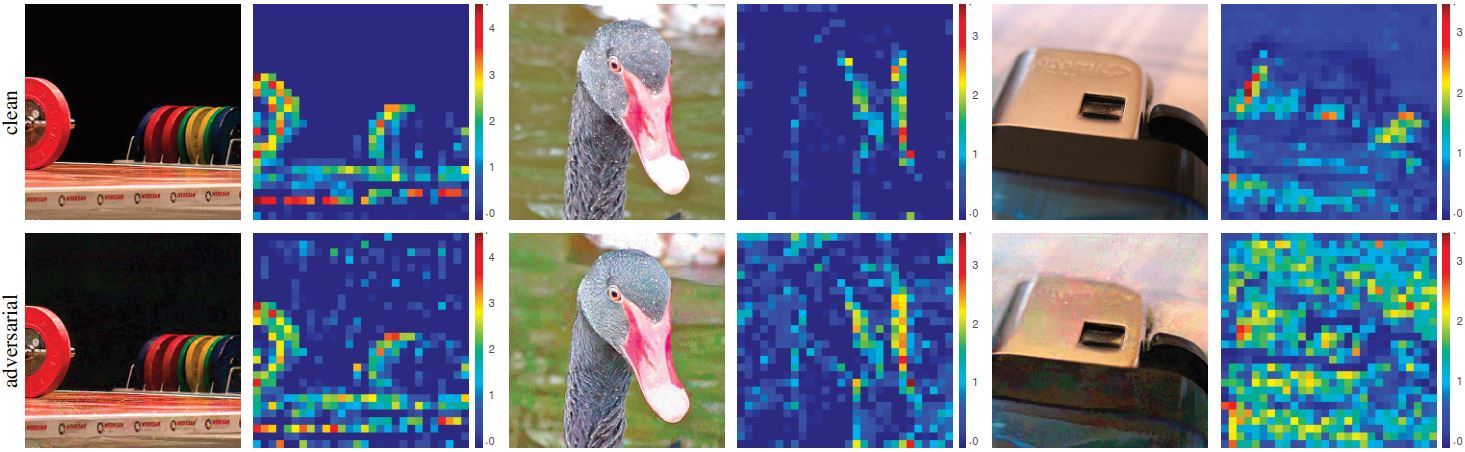
为了更清楚的描绘这个现象,作者给了更多的对抗攻击干扰网络特征提取的例子。其中最右的示例尤为明显,非常少量的噪声严重干扰了特征的提取。
针对这样的现象,作者对feature noise进行了分析,并指出
- 对扰动的约束仅在图像的pixel级别存在,而在feature层面上并没有任何的约束。
- 扰动会随着在网络中的传递而增大!
因此每经过一个层,扰动都会随之增大,直至淹没true signal,使得网络无法被正确地激活。
为了解决这个问题,作者在文章中提出在feature 上进行denoising的想法,并设计了相应的denoising 模块。
相关工作
这篇文章并不是第一个针对提高模型对抗稳定性的工作,在此之前已有一些相关的工作。常见的两种提高模型对抗稳定性的手段是对抗训练和像素去噪。
对抗训练
一种常见的对抗训练策略是ALP(Adversarial Logit Paring)。该策略旨在训练模型对同一张图像的clean与“noisy”两种版本做出相似的预测。
像素去噪
Liao et al. 提出利用high-level feature来训练学习如何对图像进行像素去噪。与其不同的是,该文章在feature上进行去噪。 Guo et al. 通过不可导的图像预处理来进行图像变换,比如整体方差最小。该方法易遭受有针对性的white-box的攻击。
Feature Denoising
Feature denoising module的整体结构如下图
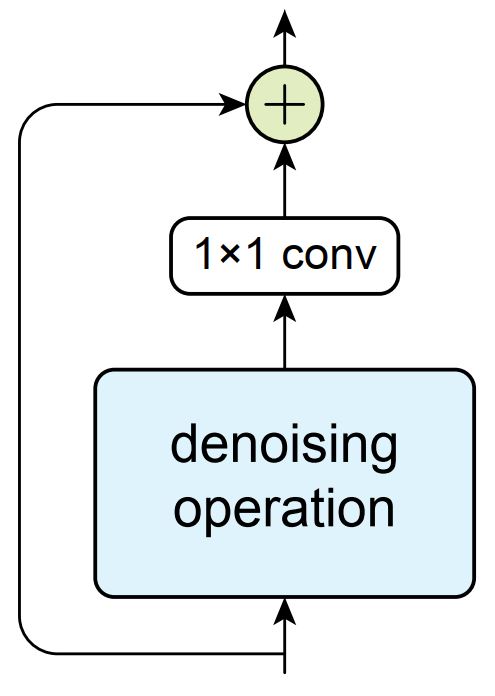
该module有三个重要的组成部分:
- denoising operation:对signal进行去噪处理
- residual connection:考虑到去噪的过程中,原始信号中的true signal也会受到影响,作者提出利用该结构来保留原始信号。
- 1×1 convolution:那么到底该在原始信号的基础上进行何种程度的去噪呢?作者提出利用这样一个1×1的卷积来让网络自行学习。
针对denoising operation部分,作者在本文中实验比较了四种filter
- non-local means filter
- bilateral filter (上者的“局部”版)
- mean filter
- median filter
Adversarial Training
作者利用PGD attacker生成了扰动的图像,并在这些图像上进行训练。
实验&结论
作者通过与baseline的对比验证了加入feature denoising module可以更好地对抗攻击。实验中有两个比较有意思的结果在这里分析下
1) residual connection必不可少
作者在ablation实验中尝试着去掉module中的某一个要素来观察不同要素对提高网络鲁棒性的影响。下表中给出了实验结果

从这里可以看出,去掉feature denoising module和 1×1 convolution 都会降低网络的表现。而去掉residual connection则会导致网络无法训练!
2) adversarial trained model for clean image
作者在这里指出,一个adversarial trained模型在clean图像上的分类准确度要低于一个clean trained模型。
某Y观点:这一点非常有趣。因为按理来说一个学会去噪的模型应该可以更好的识别clean图像,毕竟在data augmentation中有一项就是增加随机噪声(训练时既有噪声图像也有原图像)来提高网络学习时的鲁棒性。但似乎网络学会了鉴别noisy图像后就忘记了如何识别clean图像。
某Y同事观点:一切都是过拟合!哈哈哈,再贴切不过😆
感想
纵观下来,这篇文章的创新性实在有限,其denoising module的实质就是learning residual,只是对学习residual的方式加了一定的约束,例如denoising operation。然而,这确实一篇CVPR文章!为什么?原因其实很简单,就是这篇文章讲了一个很fancy的故事!
- 首先作者发现了一个很有意思的现象,并通过抓人眼球的视觉实例直截了当的让读者感受到这个现象(pixel level noise很小,但是feature level noise很大)。
- 在此基础上,作者进一步分析阐述为什么会有这种现象(随着网络的加深,noise越滚越大)。有理有据!
- 针对这种现象,作者指出现有工作的不足(仅仅在pixel level去噪是不够的),并提出自己的feature denoising module。
- 进一步这对其中的各部分进行讨论(不同filter的解释)
- 训练方法上的特别之处(adversarial training)
- 大量的试验×完美的结果×有趣分析
前面抓人眼球,中间踏踏实实,后面完美收官。于是一个好故事就诞生了!😱